Datasets¶
General Datasets¶
Suppose that the set of all choice alternatives is discrete and denoted by \(X=\{x_1,\ldots,x_m\}\).
A general dataset in this case consists of a finite collection of menus from \(X\) and the choices observed at these menus.
Datasets of this kind can be further distinguished between those with or without default/status quo options.
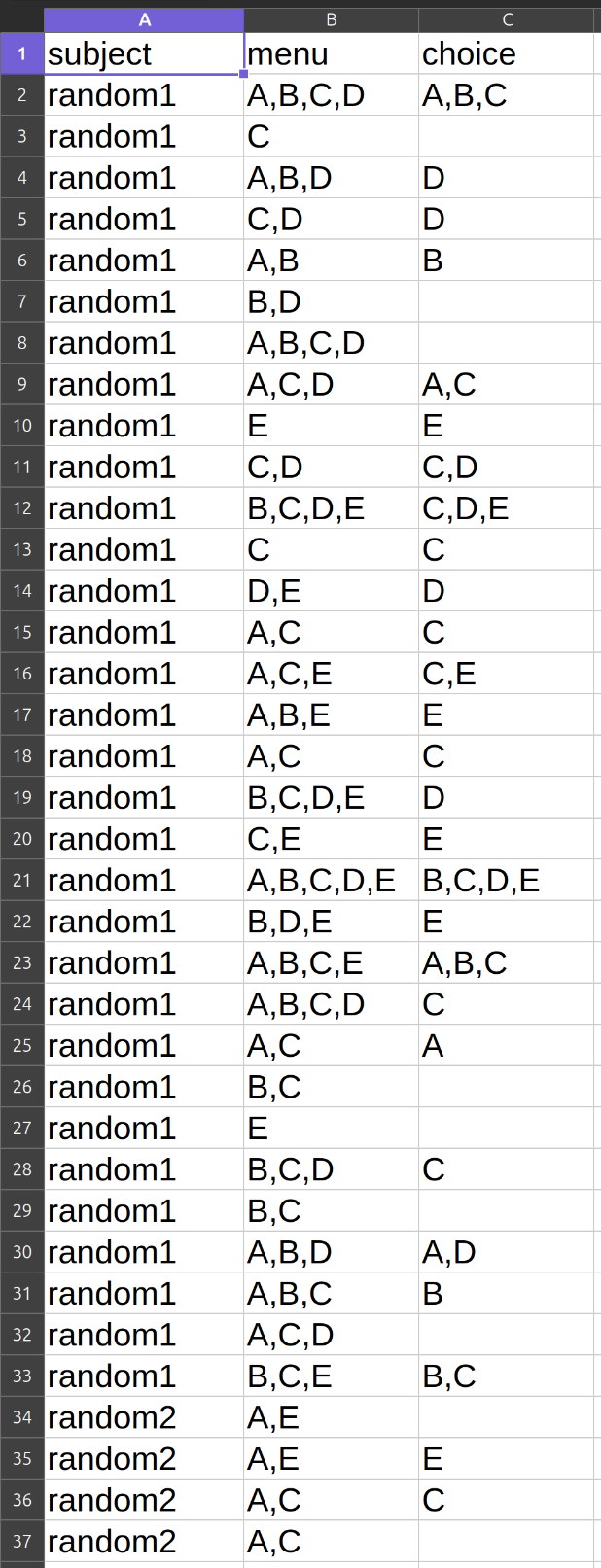
General datasets without default/status quo options¶
Such a dataset is a collection of \(k\) observations,
each of them a pair that comprises a menu \(A\subseteq X\) and the alternative(s) observed to be chosen from \(A\), if any.
The choice(s) that were observed at menu \(A\) is (are) denoted by the set \(C(A)\), where \(\emptyset\subseteq C(A)\subseteq A\).
If \(C(A)\) contains more than one alternative, it is understood that the decision maker has chosen (or may be thought of as having chosen) any or all of these alternatives at \(A\), possibly over different instances where \(A\) was presented in \(\mathcal{D}\) (see also merging).
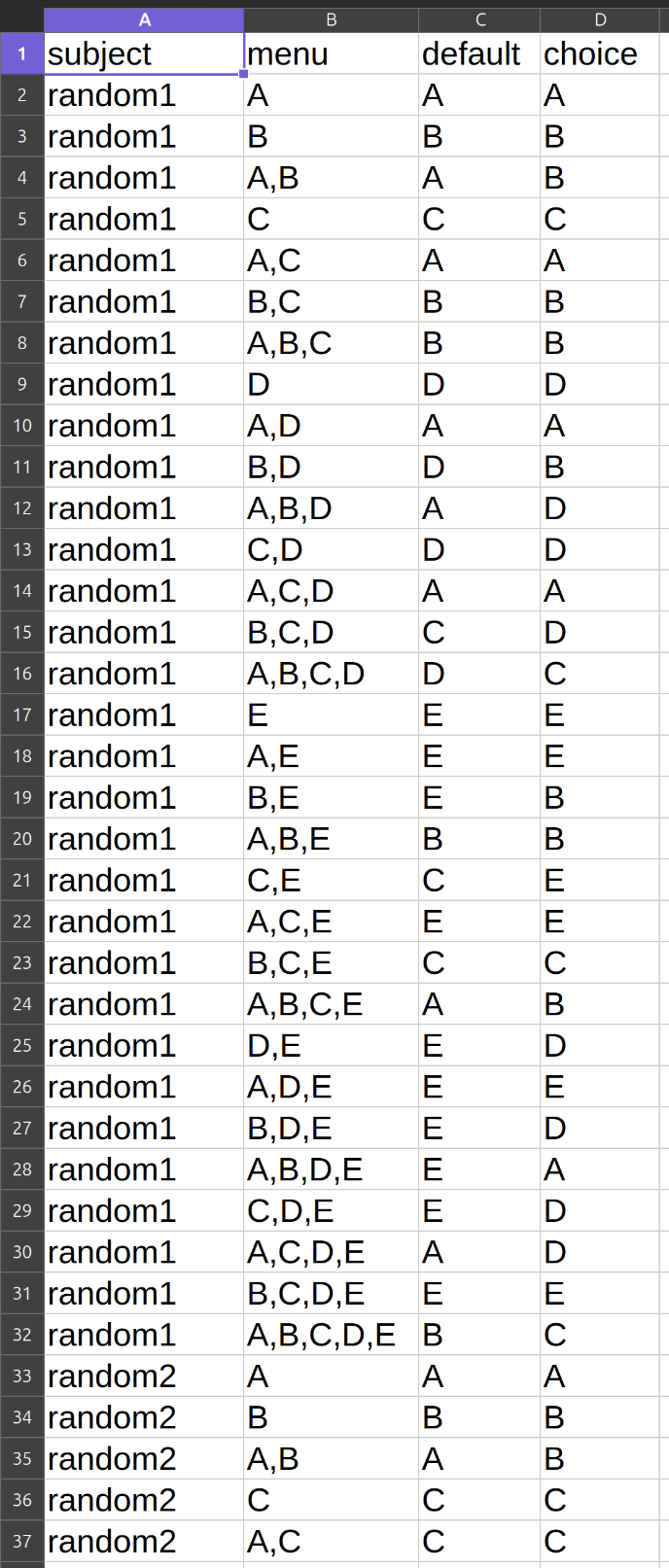
General datasets with default/status quo options¶
Such a dataset reflects situations where the decision makers under study are known to have been endowed with some alternative \(s\) in \(A\) before being observed to choose from menu \(A\).
Formally, a dataset of this kind is a collection of \(k\) observations,
The interpretation of the case where \(C(A,s)\) contains more than one alternative is the same as in the case of general datasets without default/status quo options.
The reason why \(C(A,s)\) is required to be non-empty is that, at this decision problem, the individual under study is assumed to have been endowed with an observable \(s\) at \(A\) before being observed to choose from \(A\). Hence, unlike the case of general datasets without default/status quo options, not making an active choice at \((A,s)\) means choosing the alternative \(s\) in \(A\).
Tip
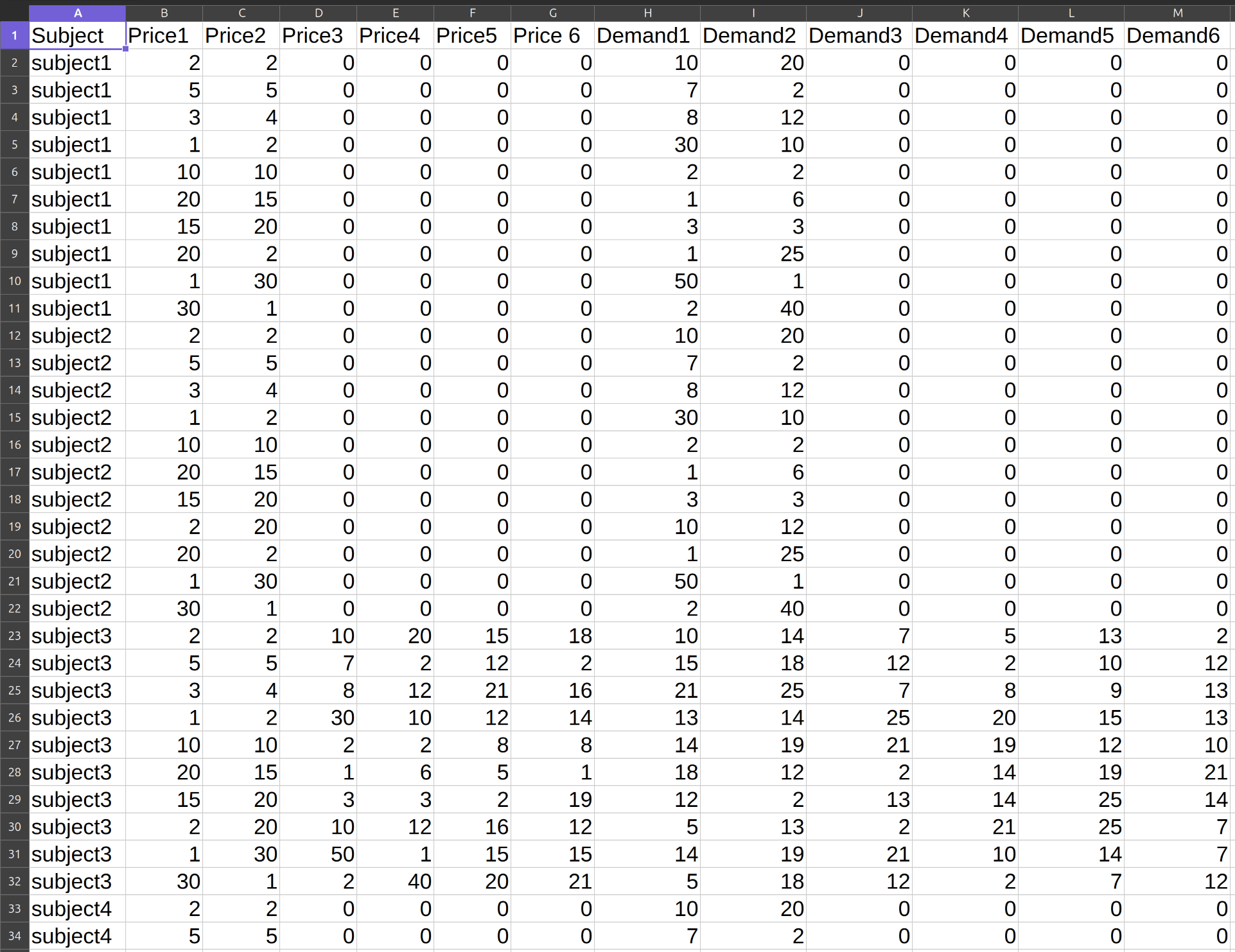
Budgetary Datasets¶
In such datasets the analyst has observed consumer choices over bundles of \(n\) commodities and the prices of these commodities.
Prices are captured by a vector \(p=(p_1,p_2,\ldots,p_n)\in\mathbb{R}^n_{+}\), where \(p_i\geq 0\) is the price of good \(i\in\{1,\ldots,n\}\).
A consumer’s demand at these prices is captured by the consumption bundle \(x(p)\in\mathbb{R}^n_+\).
A budgetary dataset
is a collection of \(k\) observations, each of them a pair \((p^i,x^i)\) comprising the consumption bundle \(x^i\) that was observed to be chosen when prices were \(p^i\).
Tip
To be analyzable by Prest, a budgetary dataset must be a .csv file.
To import such a dataset, go to “Workspace -> Import budgetary dataset” and select the target file from the relevant directory.
Budgetary datasets with \(n\) goods must have the following structure:
Column 1: subject ID
Column 2: price of good 1
Column \(n+1\): price of good \(n\)
Column \(n+2\): demand of good 1
Column \(2n+1\): demand of good \(n\)
To view the imported dataset, double-click on it in the workspace area. An extra column with the total expenditure associated with each observation is added automatically.